💥 Evaluate LLMs - OpenAI Proxy Server
A simple, fast, and lightweight OpenAI-compatible server to call 100+ LLM APIs.
LiteLLM Server supports:
- Call Huggingface/Bedrock/TogetherAI/etc. in the OpenAI ChatCompletions format
- Set custom prompt templates + model-specific configs (temperature, max_tokens, etc.)
- Caching (In-memory + Redis)
Quick Start
$ litellm --model huggingface/bigcode/starcoder
OpenAI Proxy running on http://0.0.0.0:8000
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
This will now automatically route any requests for gpt-3.5-turbo to bigcode starcoder, hosted on huggingface inference endpoints.
Other supported models:
- Bedrock
- VLLM
- OpenAI Compatible Server
- Huggingface (TGI)
- Anthropic
- TogetherAI
- Replicate
- Petals
- Palm
- Azure OpenAI
- AI21
- Cohere
$ export AWS_ACCESS_KEY_ID=""
$ export AWS_REGION_NAME="" # e.g. us-west-2
$ export AWS_SECRET_ACCESS_KEY=""
$ litellm --model bedrock/anthropic.claude-v2
$ litellm --model vllm/facebook/opt-125m
$ litellm --model openai/<model_name> --api_base <your-api-base>
$ export HUGGINGFACE_API_KEY=my-api-key #[OPTIONAL]
$ litellm --model huggingface/<huggingface-model-name> --api_base https://<your-hf-endpoint># e.g. huggingface/mistralai/Mistral-7B-v0.1
$ export ANTHROPIC_API_KEY=my-api-key
$ litellm --model claude-instant-1
$ export TOGETHERAI_API_KEY=my-api-key
$ litellm --model together_ai/lmsys/vicuna-13b-v1.5-16k
$ export REPLICATE_API_KEY=my-api-key
$ litellm \
--model replicate/meta/llama-2-70b-chat:02e509c789964a7ea8736978a43525956ef40397be9033abf9fd2badfe68c9e3
$ litellm --model petals/meta-llama/Llama-2-70b-chat-hf
$ export PALM_API_KEY=my-palm-key
$ litellm --model palm/chat-bison
$ export AZURE_API_KEY=my-api-key
$ export AZURE_API_BASE=my-api-base
$ litellm --model azure/my-deployment-name
$ export AI21_API_KEY=my-api-key
$ litellm --model j2-light
$ export COHERE_API_KEY=my-api-key
$ litellm --model command-nightly
[TUTORIAL] LM-Evaluation Harness with TGI
Evaluate LLMs 20x faster with TGI via litellm proxy's /completions endpoint.
This tutorial assumes you're using lm-evaluation-harness
Step 1: Start the local proxy
$ litellm --model huggingface/bigcode/starcoder
OpenAI Compatible Endpoint at http://0.0.0.0:8000
Step 2: Set OpenAI API Base
$ export OPENAI_API_BASE="http://0.0.0.0:8000"
Step 3: Run LM-Eval-Harness
$ python3 main.py \
--model gpt3 \
--model_args engine=huggingface/bigcode/starcoder \
--tasks hellaswag
Endpoints:
/chat/completions- chat completions endpoint to call 100+ LLMs/embeddings- embedding endpoint for Azure, OpenAI, Huggingface endpoints/models- available models on server
Set Custom Prompt Templates
LiteLLM by default checks if a model has a prompt template and applies it (e.g. if a huggingface model has a saved chat template in it's tokenizer_config.json). However, you can also set a custom prompt template on your proxy in the config.yaml:
Step 1: Save your prompt template in a config.yaml
# Model-specific parameters
model_list:
- model_name: mistral-7b # model alias
litellm_params: # actual params for litellm.completion()
model: "huggingface/mistralai/Mistral-7B-Instruct-v0.1"
api_base: "<your-api-base>"
api_key: "<your-api-key>" # [OPTIONAL] for hf inference endpoints
initial_prompt_value: "\n"
roles: {"system":{"pre_message":"<|im_start|>system\n", "post_message":"<|im_end|>"}, "assistant":{"pre_message":"<|im_start|>assistant\n","post_message":"<|im_end|>"}, "user":{"pre_message":"<|im_start|>user\n","post_message":"<|im_end|>"}}
final_prompt_value: "\n"
bos_token: "<s>"
eos_token: "</s>"
max_tokens: 4096
Step 2: Start server with config
$ litellm --config /path/to/config.yaml
Multiple Models
If you have 1 model running on a local GPU and another that's hosted (e.g. on Runpod), you can call both via the same litellm server by listing them in your config.yaml.
model_list:
- model_name: zephyr-alpha
litellm_params: # params for litellm.completion() - https://docs.litellm.ai/docs/completion/input#input---request-body
model: huggingface/HuggingFaceH4/zephyr-7b-alpha
api_base: http://0.0.0.0:8001
- model_name: zephyr-beta
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: https://<my-hosted-endpoint>
$ litellm --config /path/to/config.yaml
Evaluate model
If you're repo let's you set model name, you can call the specific model by just passing in that model's name -
import openai
openai.api_base = "http://0.0.0.0:8000"
completion = openai.ChatCompletion.create(model="zephyr-alpha", messages=[{"role": "user", "content": "Hello world"}])
print(completion.choices[0].message.content)
If you're repo only let's you specify api base, then you can add the model name to the api base passed in -
import openai
openai.api_base = "http://0.0.0.0:8000/openai/deployments/zephyr-alpha/chat/completions" # zephyr-alpha will be used
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Hello world"}])
print(completion.choices[0].message.content)
Save Model-specific params (API Base, API Keys, Temperature, etc.)
Use the router_config_template.yaml to save model-specific information like api_base, api_key, temperature, max_tokens, etc.
Step 1: Create a config.yaml file
model_list:
- model_name: gpt-3.5-turbo
litellm_params: # params for litellm.completion() - https://docs.litellm.ai/docs/completion/input#input---request-body
model: azure/chatgpt-v-2 # azure/<your-deployment-name>
api_key: your_azure_api_key
api_version: your_azure_api_version
api_base: your_azure_api_base
- model_name: mistral-7b
litellm_params:
model: ollama/mistral
api_base: your_ollama_api_base
Step 2: Start server with config
$ litellm --config /path/to/config.yaml
Model Alias
Set a model alias for your deployments.
In the config.yaml the model_name parameter is the user-facing name to use for your deployment.
E.g.: If we want to save a Huggingface TGI Mistral-7b deployment, as 'mistral-7b' for our users, we might save it as:
model_list:
- model_name: mistral-7b # ALIAS
litellm_params:
model: huggingface/mistralai/Mistral-7B-Instruct-v0.1 # ACTUAL NAME
api_key: your_huggingface_api_key # [OPTIONAL] if deployed on huggingface inference endpoints
api_base: your_api_base # url where model is deployed
Caching
Add Redis Caching to your server via environment variables
### REDIS
REDIS_HOST = ""
REDIS_PORT = ""
REDIS_PASSWORD = ""
Docker command:
docker run -e REDIST_HOST=<your-redis-host> -e REDIS_PORT=<your-redis-port> -e REDIS_PASSWORD=<your-redis-password> -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest
Logging
- Debug Logs
Print the input/output params by setting
SET_VERBOSE = "True".
Docker command:
docker run -e SET_VERBOSE="True" -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest
- Add Langfuse Logging to your server via environment variables
### LANGFUSE
LANGFUSE_PUBLIC_KEY = ""
LANGFUSE_SECRET_KEY = ""
# Optional, defaults to https://cloud.langfuse.com
LANGFUSE_HOST = "" # optional
Docker command:
docker run -e LANGFUSE_PUBLIC_KEY=<your-public-key> -e LANGFUSE_SECRET_KEY=<your-secret-key> -e LANGFUSE_HOST=<your-langfuse-host> -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest
Local Usage
$ git clone https://github.com/BerriAI/litellm.git
$ cd ./litellm/litellm_server
$ uvicorn main:app --host 0.0.0.0 --port 8000
Setting LLM API keys
This server allows two ways of passing API keys to litellm
- Environment Variables - This server by default assumes the LLM API Keys are stored in the environment variables
- Dynamic Variables passed to
/chat/completions- Set
AUTH_STRATEGY=DYNAMICin the Environment - Pass required auth params
api_key,api_base,api_versionwith the request params
- Set
- Google Cloud Run
- Render
- AWS Apprunner
Deploy on Google Cloud Run
Click the button to deploy to Google Cloud Run

On a successfull deploy your Cloud Run Shell will have this output
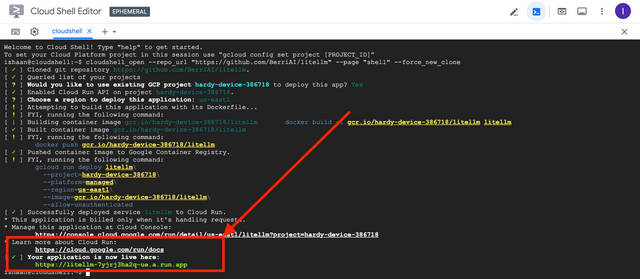
Testing your deployed server
Assuming the required keys are set as Environment Variables
https://litellm-7yjrj3ha2q-uc.a.run.app is our example server, substitute it with your deployed cloud run app
- OpenAI
- Azure
- Anthropic
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "azure/<your-deployment-name>",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-2",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7,
}'
Set LLM API Keys
Environment Variables
More info here
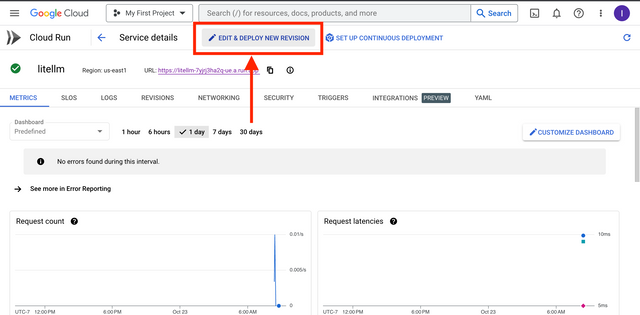
In the Google Cloud console, go to Cloud Run: Go to Cloud Run
Click on the litellm service

Click Edit and Deploy New Revision
Enter your Environment Variables Example
OPENAI_API_KEY,ANTHROPIC_API_KEY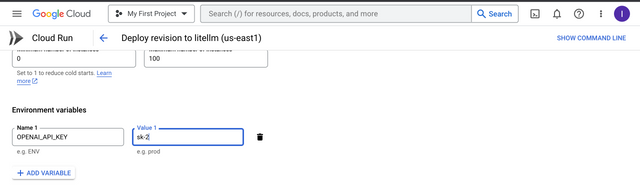
Deploy on Render
Click the button to deploy to Render

On a successfull deploy https://dashboard.render.com/ should display the following
Deploy on AWS Apprunner
Fork LiteLLM https://github.com/BerriAI/litellm
Navigate to to App Runner on AWS Console: https://console.aws.amazon.com/apprunner/home#/services
Follow the steps in the video below
Testing your deployed endpoint
Assuming the required keys are set as Environment Variables Example:
OPENAI_API_KEYhttps://b2w6emmkzp.us-east-1.awsapprunner.com is our example server, substitute it with your deployed apprunner endpoint
- OpenAI
- Azure
- Anthropic
curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "azure/<your-deployment-name>",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-2",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7,
}'
Advanced
Caching - Completion() and Embedding() Responses
Enable caching by adding the following credentials to your server environment
REDIS_HOST = "" # REDIS_HOST='redis-18841.c274.us-east-1-3.ec2.cloud.redislabs.com'
REDIS_PORT = "" # REDIS_PORT='18841'
REDIS_PASSWORD = "" # REDIS_PASSWORD='liteLlmIsAmazing'
Test Caching
Send the same request twice:
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
Control caching per completion request
Caching can be switched on/off per /chat/completions request
- Caching on for completion - pass
caching=True:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": true
}' - Caching off for completion - pass
caching=False:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": false
}'
Tutorials (Chat-UI, NeMO-Guardrails, PromptTools, Phoenix ArizeAI, Langchain, ragas, LlamaIndex, etc.)
Start server:
`docker run -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest`
The server is now live on http://0.0.0.0:8000
- Chat UI
- NeMO-Guardrails
- PromptTools
- ArizeAI
- Langchain
- ragas
- Llama Index
Here's the docker-compose.yml for running LiteLLM Server with Mckay Wrigley's Chat-UI:
version: '3'
services:
container1:
image: ghcr.io/berriai/litellm:latest
ports:
- '8000:8000'
environment:
- PORT=8000
- OPENAI_API_KEY=<your-openai-key>
container2:
image: ghcr.io/mckaywrigley/chatbot-ui:main
ports:
- '3000:3000'
environment:
- OPENAI_API_KEY=my-fake-key
- OPENAI_API_HOST=http://container1:8000
Run this via:
docker-compose up
Adding NeMO-Guardrails to Bedrock
- Start server
`docker run -e PORT=8000 -e AWS_ACCESS_KEY_ID=<your-aws-access-key> -e AWS_SECRET_ACCESS_KEY=<your-aws-secret-key> -p 8000:8000 ghcr.io/berriai/litellm:latest`
- Install dependencies
pip install nemoguardrails langchain
- Run script
import openai
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="bedrock/anthropic.claude-v2", openai_api_base="http://0.0.0.0:8000", openai_api_key="my-fake-key")
from nemoguardrails import LLMRails, RailsConfig
config = RailsConfig.from_path("./config.yml")
app = LLMRails(config, llm=llm)
new_message = app.generate(messages=[{
"role": "user",
"content": "Hello! What can you do for me?"
}])
Use PromptTools for evaluating different LLMs
- Start server
`docker run -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest`
- Install dependencies
pip install prompttools
- Run script
import os
os.environ['DEBUG']="" # Set this to "" to call OpenAI's API
os.environ['AZURE_OPENAI_KEY'] = "my-api-key" # Insert your key here
from typing import Dict, List
from prompttools.experiment import OpenAIChatExperiment
models = ["gpt-3.5-turbo", "gpt-3.5-turbo-0613"]
messages = [
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who was the first president?"},
]
]
temperatures = [0.0, 1.0]
# You can add more parameters that you'd like to test here.
experiment = OpenAIChatExperiment(models, messages, temperature=temperatures, azure_openai_service_configs={"AZURE_OPENAI_ENDPOINT": "http://0.0.0.0:8000", "API_TYPE": "azure", "API_VERSION": "2023-05-15"})
Use Arize AI's LLM Evals to evaluate different LLMs
- Start server
`docker run -e PORT=8000 -p 8000:8000 ghcr.io/berriai/litellm:latest`
Use this LLM Evals Quickstart colab
Call the model

import openai
## SET API BASE + PROVIDER KEY
openai.api_base = "http://0.0.0.0:8000
openai.api_key = "my-anthropic-key"
## CALL MODEL
model = OpenAIModel(
model_name="claude-2",
temperature=0.0,
)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import AIMessage, HumanMessage, SystemMessage
chat = ChatOpenAI(model_name="claude-instant-1", openai_api_key="my-anthropic-key", openai_api_base="http://0.0.0.0:8000")
messages = [
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(
content="Translate this sentence from English to French. I love programming."
),
]
chat(messages)
Evaluating with Open-Source LLMs
Use Ragas to evaluate LLMs for RAG-scenarios.
from langchain.chat_models import ChatOpenAI
inference_server_url = "http://localhost:8080/v1"
chat = ChatOpenAI(
model="bedrock/anthropic.claude-v2",
openai_api_key="no-key",
openai_api_base=inference_server_url,
max_tokens=5,
temperature=0,
)
from ragas.metrics import (
context_precision,
answer_relevancy,
faithfulness,
context_recall,
)
from ragas.metrics.critique import harmfulness
# change the LLM
faithfulness.llm.langchain_llm = chat
answer_relevancy.llm.langchain_llm = chat
context_precision.llm.langchain_llm = chat
context_recall.llm.langchain_llm = chat
harmfulness.llm.langchain_llm = chat
# evaluate
from ragas import evaluate
result = evaluate(
fiqa_eval["baseline"].select(range(5)), # showing only 5 for demonstration
metrics=[faithfulness],
)
result
!pip install llama-index
from llama_index.llms import OpenAI
response = OpenAI(model="claude-2", api_key="your-anthropic-key",api_base="http://0.0.0.0:8000").complete('Paul Graham is ')
print(response)